ELECTRIC OPRPHEUS ACADEMY
SPILLING THE BEANS #8 TRAMP
Following a suggestion, I looked through my old spatial
motion algorithms once again: the model of the movement of a sound source
in the plane and its
projection on 2 or 4 loudspeakers. At the end of the Eighties I conceived
these algorithms (NMS4, still under DOS) and used them from time to time
between 1990 and 1996 (STEINBUTT-VARIATIONEN, Werke 9, ccr409; PASSANTEN,
Werke 10, ccr410).
Now I have reworked one of them and have adapted
it to the standards of AMP as a new core object:
TRAMP
The basis of it, the movement of a point in one plane
that represents the virtual position of a sounding object (please do not
mistaken it with 'sound object'!)
at every moment, is available in two ways:
tramp.fromto
The movement takes place linearly between
two positions (from – to), which can be defined as parameter pairs.
tramp.trace
A control input predetermines the position
of the sounding object for each moment on two tracks interpreted as coordinates.
According to these positions, the panorama distribution onto the different
tracks is calculated at every moment, as are the delays and filterings.
Because the distance to the center continuously changes, movement phenomena
such as the Doppler effect result automatically if the radial movement
component is strong enough.
What's new is that
the module is not only executed in stereo and quadro, but for any arbitrary
number of tracks, whereby one has to imagine that the loudspeakers are
set up in a circle.
The number of possible tracks is practically limited to 96 at present,
but can be extended at any time.
Of course, an uneven number of tracks work, too, as does mono. (Because
the phenomenology of an even movement can also be conveyed with only one
loudspeaker).
It is a model. It should also not be more than that; illusionary perfection
is far from my intention. [Here
is not the place to talk about the 'subtle' difference between illustration
and illusion. An extensive discussion about this, however, is long overdue].
The Model
First of all, the volume which the sounding object is perceived with decreases
with its distance. It is clear, but according to which function? Here
we already have the first obstacle.
Generations of acoustic textbooks teach: with the square of the distance.
(The acoustician differentiates between 'sound pressure' and 'sound intensity'.
That should not mislead us here. It is a matter of amplitude for us, thus
sound pressure). Others maintain that it is simply inverse to the distance.
A respected Berlin sound engineer, who vehemently advocates the second
thesis, has started a proper campaign against the spreading of 'false
teachings', in the course of which I also had the honor of being placed
on the index of false teachings, because I had brought the square variant
into play in my scripts about volume.
However, I had already taken the problem into account in NMS4. The exponent
(whether 1/distance, 1/distance² or also 1/distance³...) is
arbitrarily selectable. This option is contained in the current version
of AMP.
One can try it out – akueto! (one
listen!)
The experimental preoccupation with it namely shows the following:
1/d² is indeed too extreme, the sound disappears unnaturally quickly
in the distance.
1/d, on the other hand, is too flat. One will not rid oneself of the sound,
also in larger distances.
Hence, an exponent between 1 and 2? – Stupid, because the calculation
effort for non-integer exponents thus increases tremendously. However,
as an alternative there is an exponent 3/2, which lies between 1 and 2
and does not require so much effort to calculate.
Perhaps the controversy will be resolved to
everyone's satisfaction
if the simple question is permitted: for which frequency, please?
Naturally, we hear extremely low frequencies over many kilometers, middle
frequencies hardly, and higher ones not at all – a filter, then.
Such a filter is now implemented (>>Spilling the Beans #1 lprun).
A so-called 'steady state filter' that can be adjusted to the distance
at each moment.
A second aspect is the angle of incidence from
which the distribution of the signal to the loudspeakers standing in a
circle is derived. As to that, there are 2 variants:
1) stereo panning (default)
The sound from any direction will be constantly projected on only two
adjacent loudspeakers.
That has the big advantage that the calculation effort for, let us say,
1000 tracks would be hardly larger than for 3.
However, it has the fatal disadvantage that each loudspeaker has to be
able to bring the maximum full-range performance to achieve a fairly rich
sound.
2) wide
In principle, always half of all loudspeakers will be addressed ((n+1)/2
for an odd number). In this way, the amount of electric power is distributed,
but the calculation effort again increases accordingly.
Such an algorithm requires a good deal of constants,
which in part correspond to physical constants (sonic speed, decrease
of the volume with the distance, etc.), and in part fulfill only technical
functions. These constants are fixed, yet are also executed as parameters,
whereby they also are available experimentally.
Reflectors
An arbitrary number of reflection points can be placed in the layer. Going
from the position of the sounding object, the run times, amplitudes and
filterings at every moment will be calculated through these reflections.
At least first reflections are presentable in this way. Second reflections
(the way from the sounding object to a reflector, from this to another
reflector, and from there to the monitoring center) would indeed be possible;
I doubt, however, that the calculation effort is worth it. With a well-tuned
delay feedback, a similar back filling,
which smoothes the disparate echoes somewhat in the direction of a reverb,
can be achieved in a simple manner.
A freeze from Mozart's minuet, which rolls by us at 120 km/h:
The phasing effects result through two reflectors near
the monitoring point.
Traces
Firstly, all geometric figures that are able to be developed in the time
are suited for controlling the movement through a control input. With a
scaling factor (in meters), they can be interpreted in the desired size.
John Chowning, e.g., supposedly uses Lissajous figures to control the four-channel
panorama in his piece TURENAS (1980-81). [I still possess
a copy of it on tape from my festival ABSOLUTE MUSIK 1989. For a performance,
however, one would have to request a digital copy].
Such figures are created when one generates sine
waves of different frequencies in both channels:
gen.lissajous 1hz,1.4hz

One gets adventurous figures if one replaces the sine
waves with lemniscates that stand on each other vertically (>> Spilling
the Beans #7):
gen.lissajous.lem 1hz,1.4hz sfload frank.wav; stretch 1000; view. sfload frank.wav; hilb; stretch 1000; view.
Sound files in extremely slow tempo can also be used to control the trace
if they have a somewhat broad stereo basis or are complex.
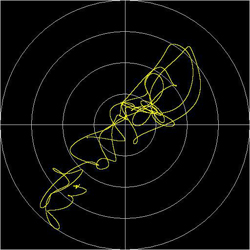
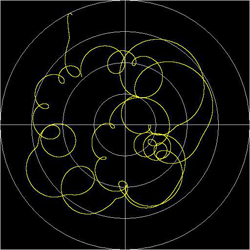
The same freeze, now on the trace predetermined
by the lemniscates:
The control of the trace follows in this case through the previous freeze in 1/300 tempo.
(If possible, listen to it over loudspeakers that also create bass!).
Everything works, as said, multi-track as well. Whereby I would say that it first starts getting interesting as of 6 channels. With 4 channels the intermediate areas are still too diffuse.
* * *
If one renounces the movement and works with fixed positions of the sounding object, then the method reduces to a system of reflections, echoes. The computing power then diminishes considerably, because the constant trigonometric realignments are discontinued.
Instead, one could increase the number of reflection points and add secondary reflections. With a few finesses more, arbitrary spatial impulse responses can be approached (>> Spilling the Beans #6). Also in a way that one can assign different sound sources different positions in the space.
More about that coming soon.
akueto
G.R.
(c) Günther Rabl 2010